Appearance
快速入门
该平台是面向AI开发者的一站式开发平台,通过AI开发全流程管理助您智能、高效地创建AI模型和一键部署到云、边、端。
该平台不仅支持自动学习功能,还预置了多种已训练好的模型,同时集成了Jupyter Notebook,提供在线的代码开发环境。
根据习惯选择您的使用方式
- 如果您是没有AI开发经验,您可以使用自助建模功能,进行零基础构建AI模型,详情见自助建模
- 如果您有一定的AI基础,您可以使用图形化建模功能,使用封装好的算法组件,进行拖拽、连线、参数配置,从而得到新模型,详情见图形化建模
- 如果您熟悉代码编写和调测,您可以使用编码式建模功能,在线代码开发环境,编写训练代码进行AI模型的开发,详情见编码式建模
- 如果您想通过数据中台算力进行模型训练,详情见数据中台融合
自助建模
针对没有AI开发经验的使用者,平台提供了自助建模功能,无需关注模型开发、参数调整等开发细节,仅需二步(数据准备、自动训练部署),即可完成一个AI开发项目。
本章节提供了一个“鳄鱼检测”样例,帮助您快速熟悉自助建模的使用过程。此样例为“物体检测”类别项目,通过预置的鳄鱼图像数据集,自动训练并生成检测模型,同时将生成的模型部署为在线服务。部署完成后,用户可通过在线预测功能输入图片是否包含鳄鱼。
开始使用样例前,请仔细阅读准备工作罗列的要求,提前完成准备工作。使用自助建模功能完成模型构建的步骤如下所示:
- 步骤一:准备数据
- 步骤二:创建物体检测实验
- 步骤三:自动训练、部署
- 步骤四:预测服务
准备工作
- 已注册思特奇账号
- 有模型算法开发者的角色
步骤一:准备数据
在公共数据集中,平台提供了鳄鱼的实例数据集,命名为“zebra-croc”,您需要先在数据集管理模块,将该公共数据集拷贝到自己的空间内
如果您想使用自己的数据集,可跳过此步骤,需注意,不同的模型类型会有不同的标注格式、文件目录要求,请上传符合要求的数据,否则会影响使用,具体要求如下:
1.1 目标检测模型
1.1.1 标注数据格式说明
每个图片的标注数据, 存放到单独的一个文本文件中, 文件中每行一个标注记录, ","作为列分隔符, 记录格式描述如下:
- 检测目标为4边形, 前面8个浮点数字为4个顶点顺时针循序的x/y坐标, 坐标值为像素位置
- 最后一列数据为目标的标签名称, 样例如下:
530.0,656.0,1404.0,458.0,1382.0,620.0,554.0,758.0,"刀型标签"
730.0,894.0,700.0,1466.0,870.0,1474.0,826.0,926.0,"刀型标签"
图片大小不限, 模型训练过程会自动resize到设定的大小, 支持.jpg格式
1.1.2 目录结构说明
单个目录, 目录下每个图片文件对应相同文件名的txt文件保存标注数据, 下面是目录样例:
ls val
252298106_1003.jpg 253881119_1003.txt 255361461_1003.jpg 256979134_1003.txt 258538671_1003.jpg 260252547_1003.txt
252298106_1003.txt 253887349_1003.jpg 255361461_1003.txt 257033813_1003.jpg 258538671_1003.txt 260283430_1003.jpg
所有图片保存在单个目录中, 训练的预处理过程中拆分训练集和测试集, 比例由输入参数确定
2.1 图片分类ofa模型
2.1.1 标注数据说明
图片分类无单独的标注数据
2.1.2 目录结构说明
目录结构分为两层, 第一层为类别目录, 每个目录名即为类别的名称, 图片文件按照各自的类别存放于对应的目录中, 样例如下:
ls -R
.:
cat dog
./cat:
cat1.jpg cat11.jpg cat13.jpg cat15.jpg cat3.jpg cat5.jpg cat7.jpg cat9.jpg
cat10.jpg cat12.jpg cat14.jpg cat2.jpg cat4.jpg cat6.jpg cat8.jpg
./dog:
dog1.jpg dog11.jpg dog13.jpg dog15.jpg dog3.jpg dog5.jpg dog7.jpg dog9.jpg
dog10.jpg dog12.jpg dog14.jpg dog2.jpg dog4.jpg dog6.jpg dog8.jpg
3.1 yolo目标检测模型
3.1.1 标注格式说明
标注数据保存于每个图片文件对应一个相同名称的 .txt 文件中, 在labels目录中, 其数据为yolo格式, 描述如下:
- One row per object, 每行一个目标
- Each row is class x_center y_center width height format. 每行的列值为: 类别id 中心点x 中心点y 宽度 高度, 空格分隔列.
- Box coordinates must be normalized by the dimensions of the image (i.e. have values between 0 and 1): 框的座标值做了归一化处理, 值在0.0~1.0之间
- Class numbers are zero-indexed (start from 0). 分类编号从0开始
样例(无header):
类别id 中心点x 中心点y 宽度 高度
3 0.600 0.441 0.053 0.062
0 0.552 0.448 0.057 0.110
0 0.498 0.475 0.037 0.070
0 0.308 0.598 0.037 0.040
0 0.203 0.604 0.013 0.018
0 0.237 0.557 0.013 0.020
3 0.745 0.589 0.030 0.022
3 0.432 0.598 0.017 0.015
3.1.2 目录结构说明
数据集目录包含两级, 第一级包含两个目录一个文件, 分别为图片目录 images, 标注数据目录labels, 类别文件 classes.txt; 其中images目录下保存全部的图片文件, 支持png jpg等, 不限大小, 训练和验证时会自动根据模型要求resize; labels目录下保存按图片的标注文件, 每个文件对应images目录中的一个图片文件, 其文件名相同而扩展名为.txt
样例如下:
ls -R
.:
classes.txt images labels
./images:
road0.png road187.png road275.png road363.png road451.png road54.png road628.png road716.png road804.png
...
./labels:
road0.txt road187.txt road275.txt road363.txt road451.txt road54.txt road628.txt road716.txt road804.txt
road1.txt road188.txt road276.txt road364.txt road452.txt road540.txt road629.txt road717.txt road805.txt
road10.txt road189.txt road277.txt road365.txt road453.txt road541.txt road63.txt road718.txt road806.txt
...
步骤二:创建物体检测实验
- 准备好数据集后,点击菜单的“自助建模”;
- 进入模块后,点击新增按钮;
- 选择一级实验类型为“图片”,二级实验类型为“物体检测”,模型选择“YOLO目标检测模型”;
- 进入新增页面,输入实验名称、描述,选择准备好的数据集,点击页面右下角的“执行”按钮。
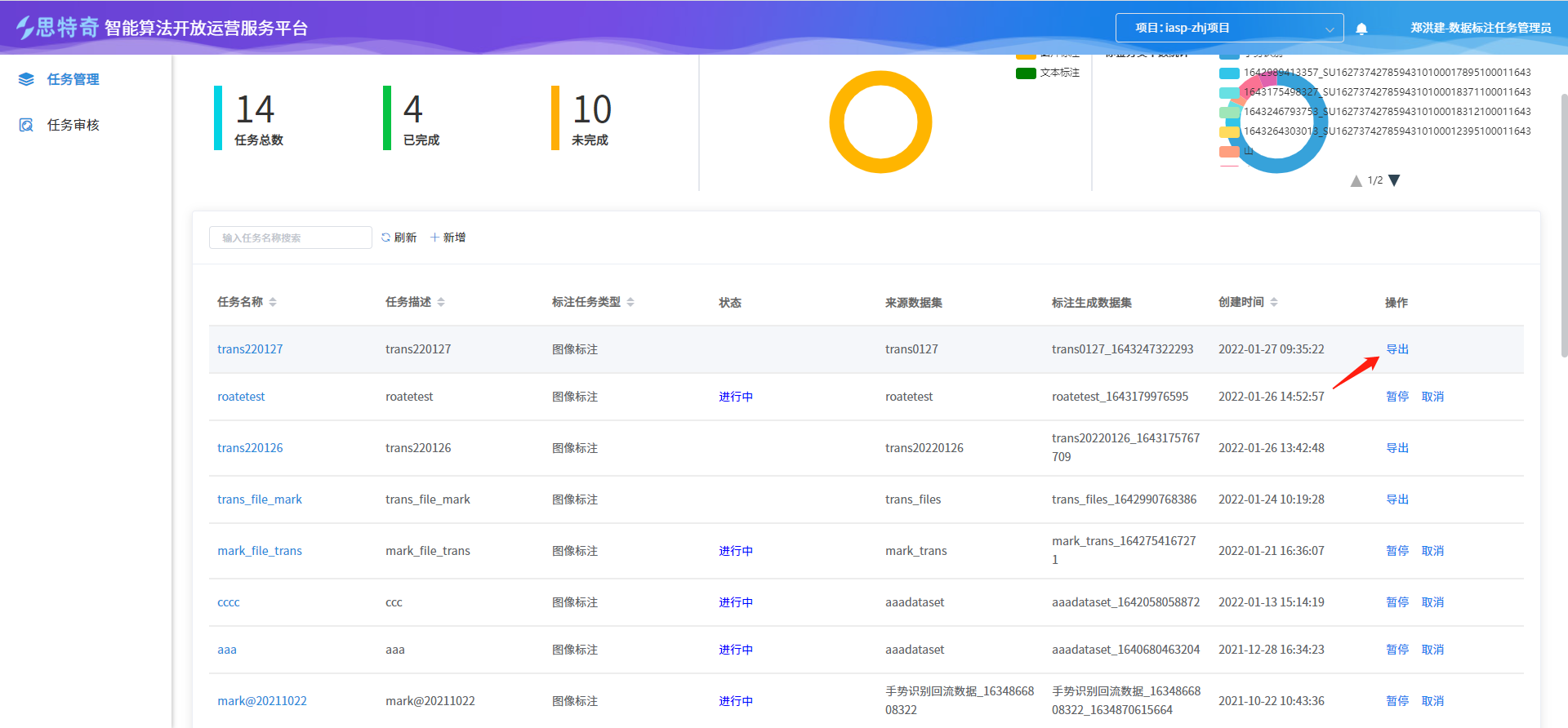
步骤三:自动训练、部署
在自助建模模块,进入训练记录页面,查看最新的训练状态,当是“正常结束”状态后说明可以进入下一步
步骤四:预测服务
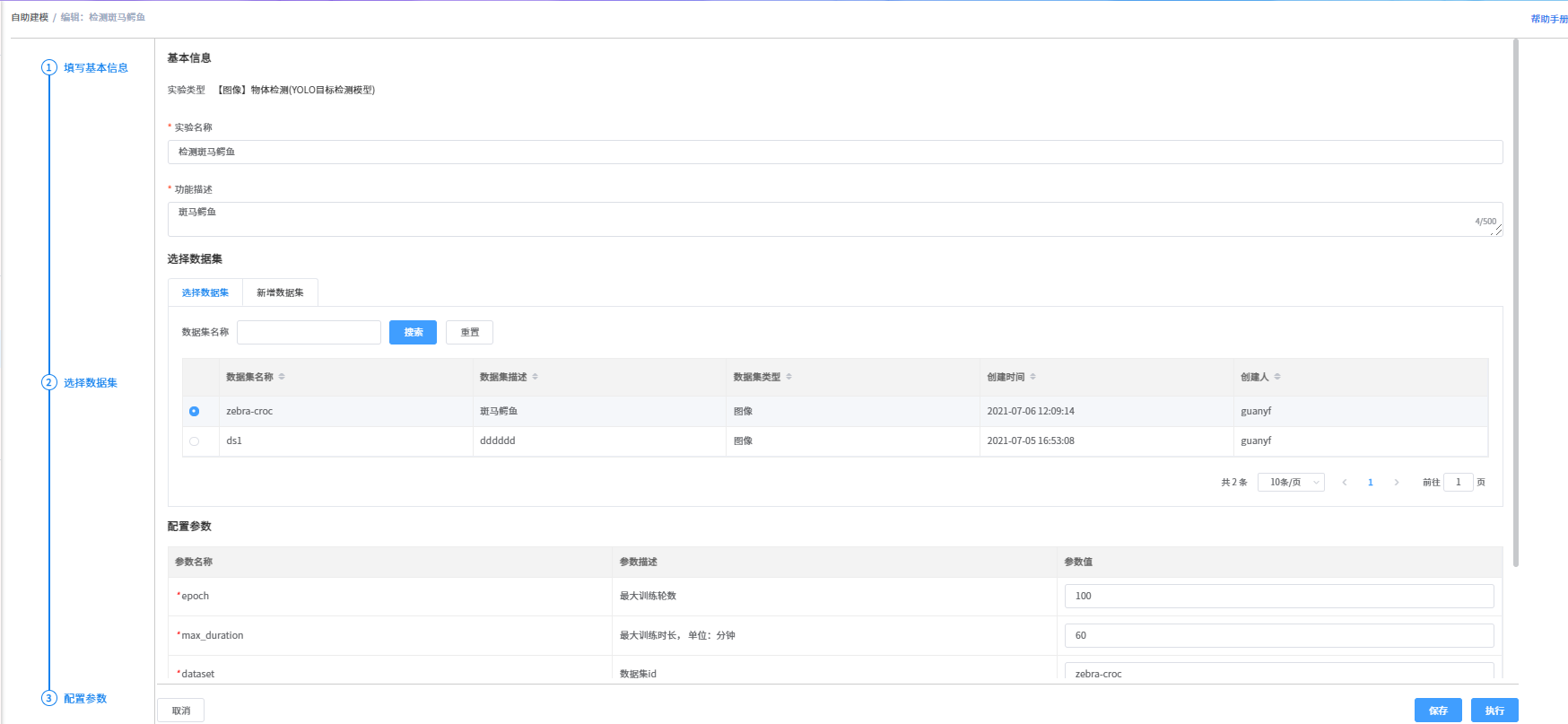
在自助建模模块,点击实验对应行后的“预测”按钮,进入预测页面,点击“文件上传”按钮,上传预测图片后,点击“开始预测”按钮,一段时间后,右侧预测结果区域会显示预测结果 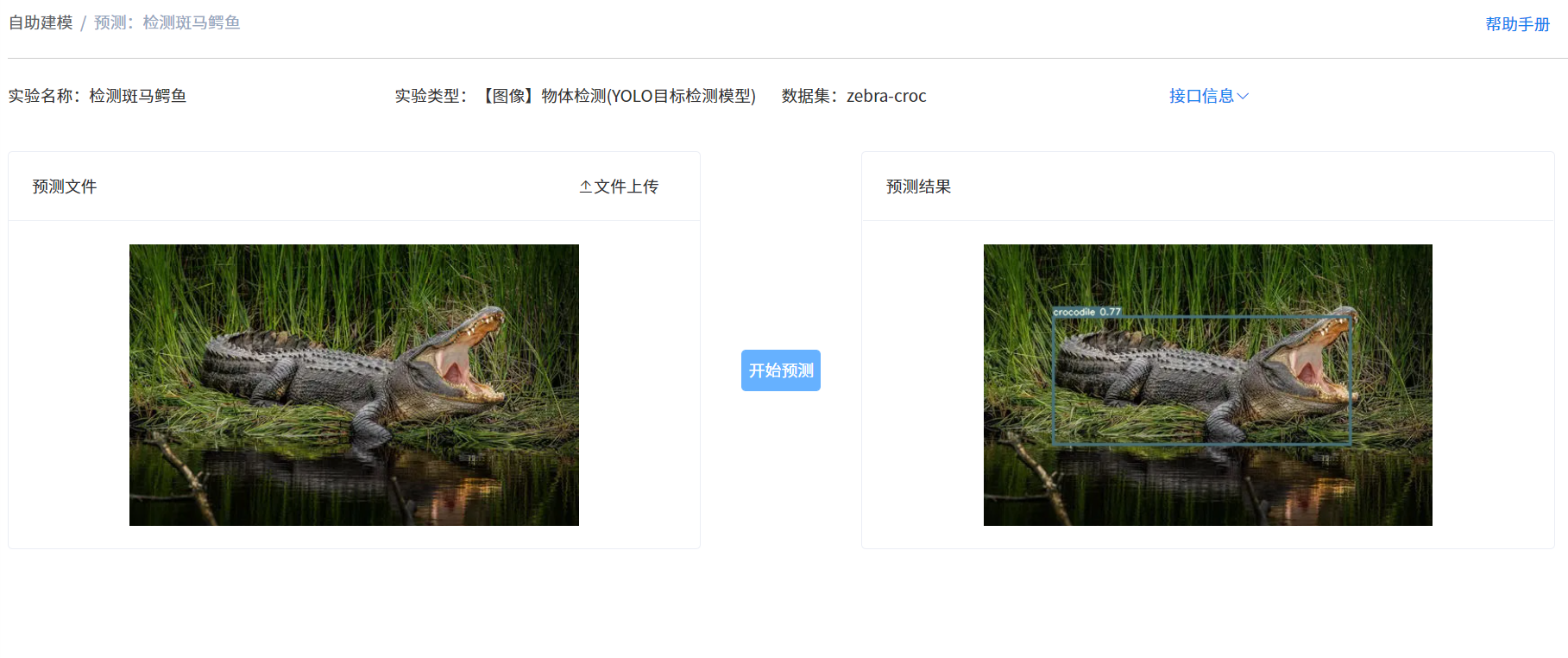
modelOps流水线建模
平台提供拖拉拽方式的建模流程操作,以流程组件方式进行流程的创建,使用者只需关注每个组件的属性参数以及连接关系等信息。
本章节提供了一个文本分类流程的演示样例,帮助您快速了解modelOps
开始使用样例前,请仔细阅读准备工作罗列的要求,提前完成准备工作,步骤如下:
- 步骤一:进行文本分类流程组件拖拽连接
- 步骤二:组件属性参数设置及启动
- 步骤三:查询组件执行结果数据及执行状态
步骤一:进行文本分类流程组件拖拽连接
- 打开图形化建模模块,选择文本分类组件目录下节点组件
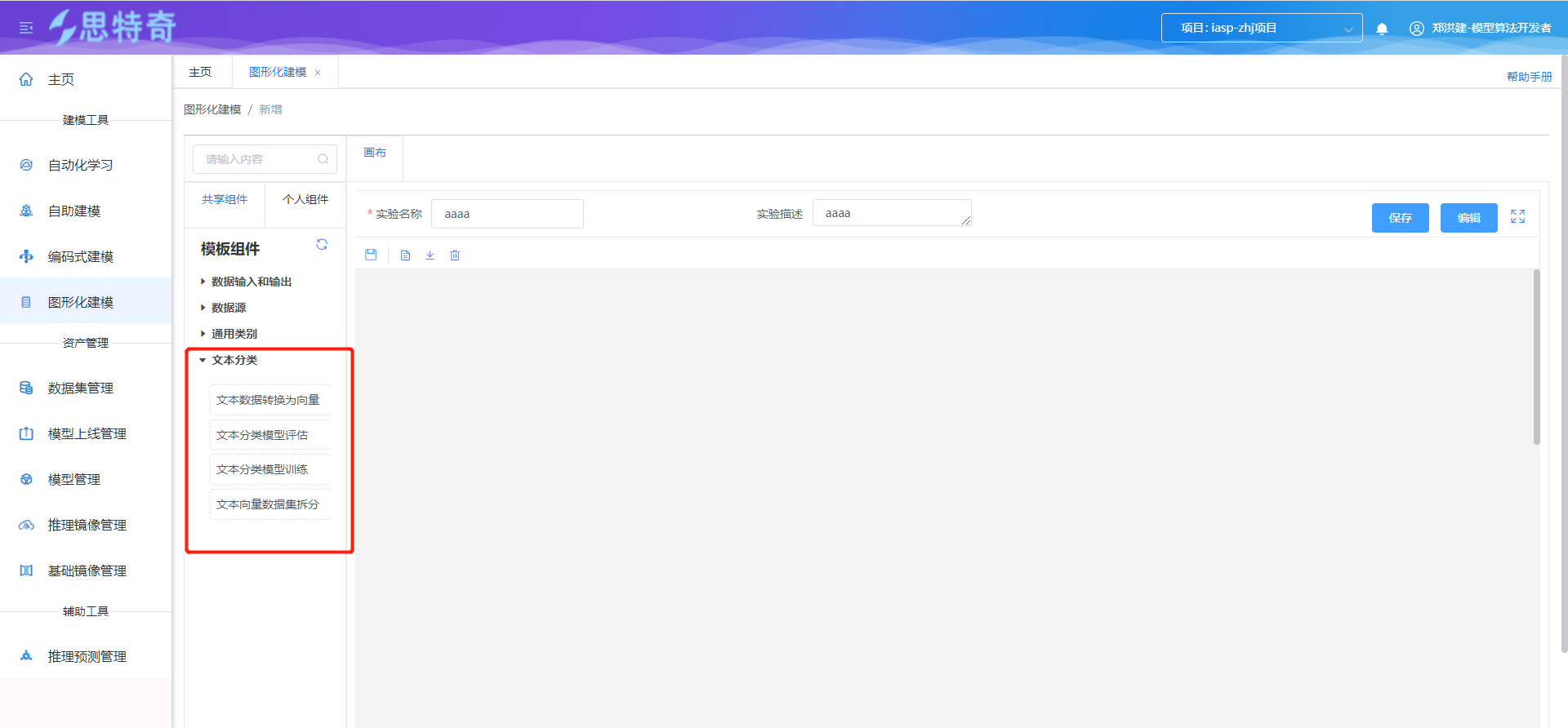
- 根据文本分类执行流程进行组件拖拽
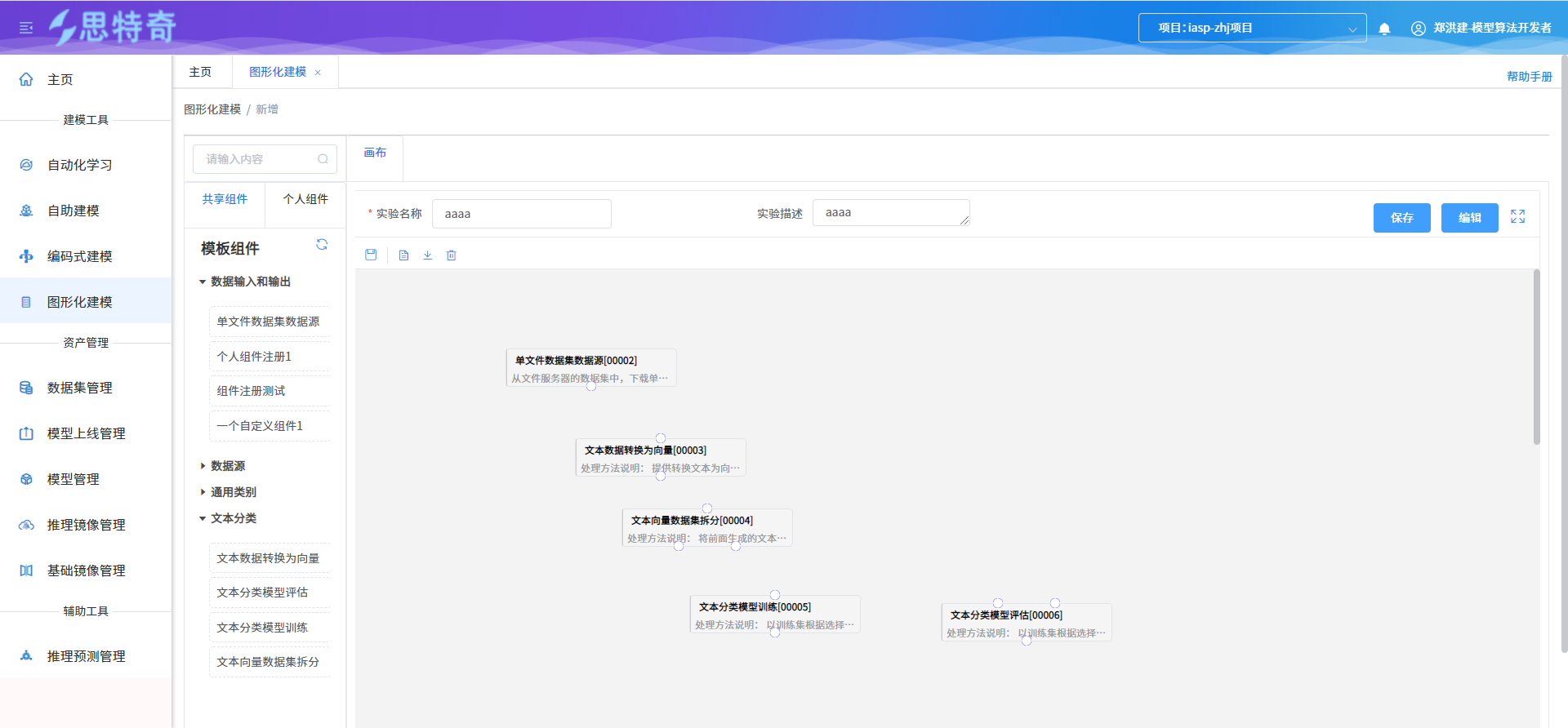
- 各组件进行关联连接
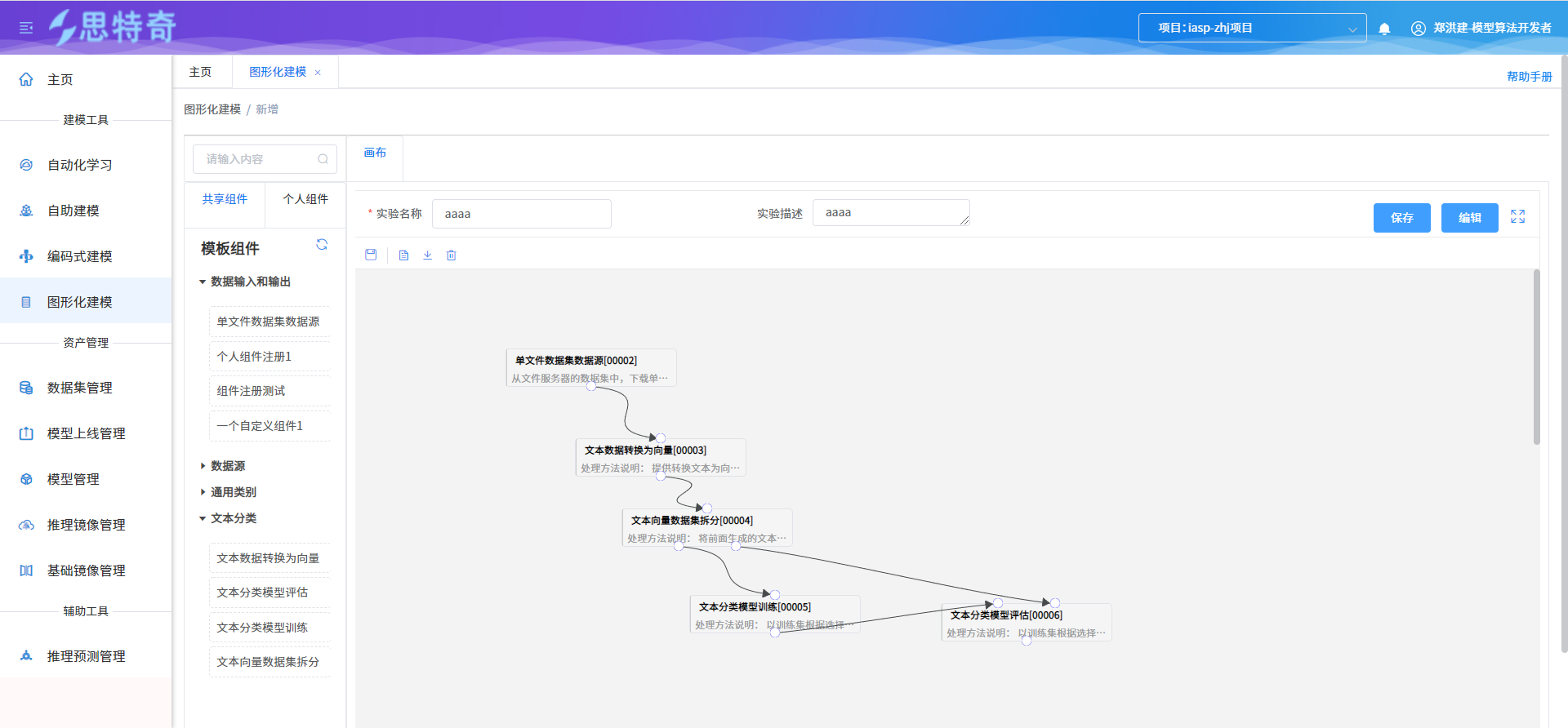
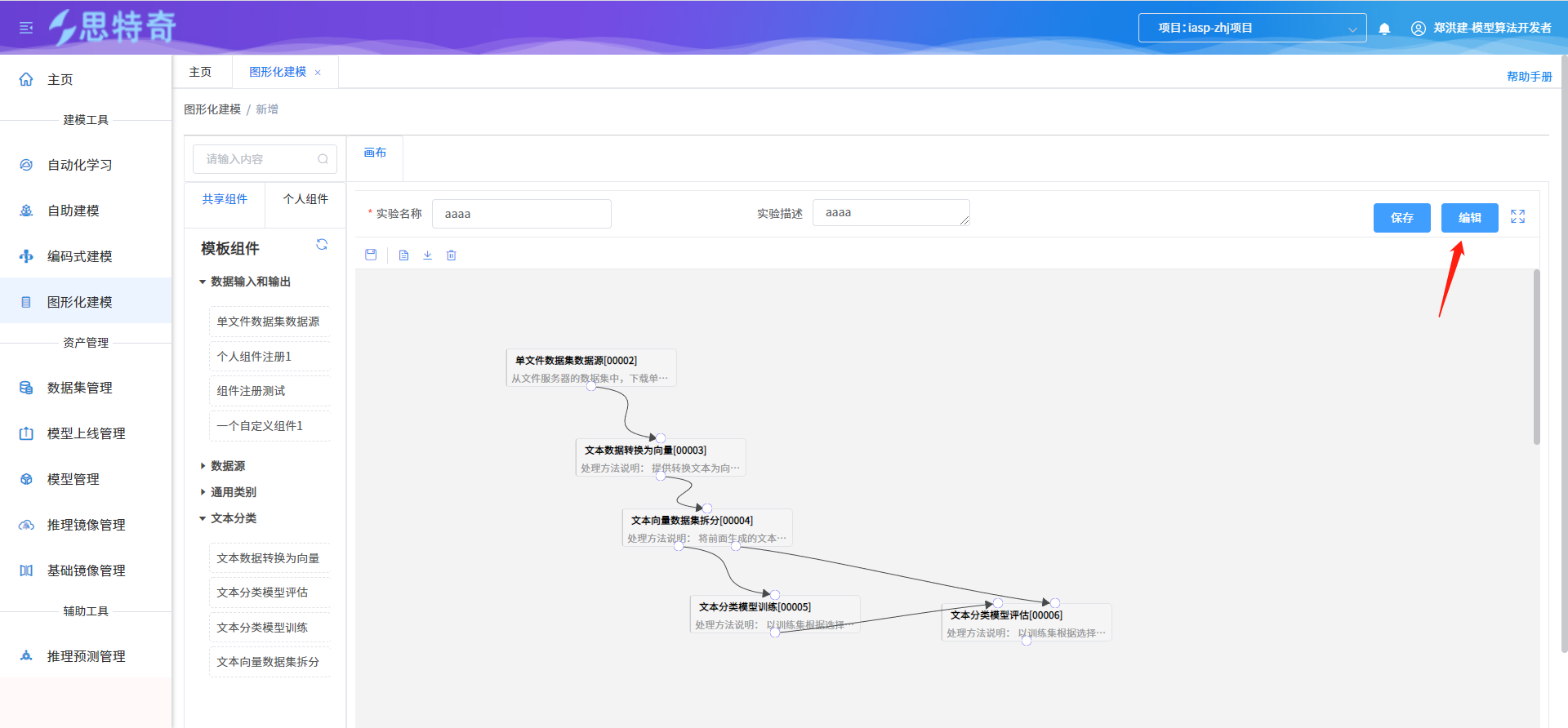
步骤二:组件属性参数设置及启动
- 通过点击编辑按钮进入流程编辑模式,并同时分配流程运行环境容器
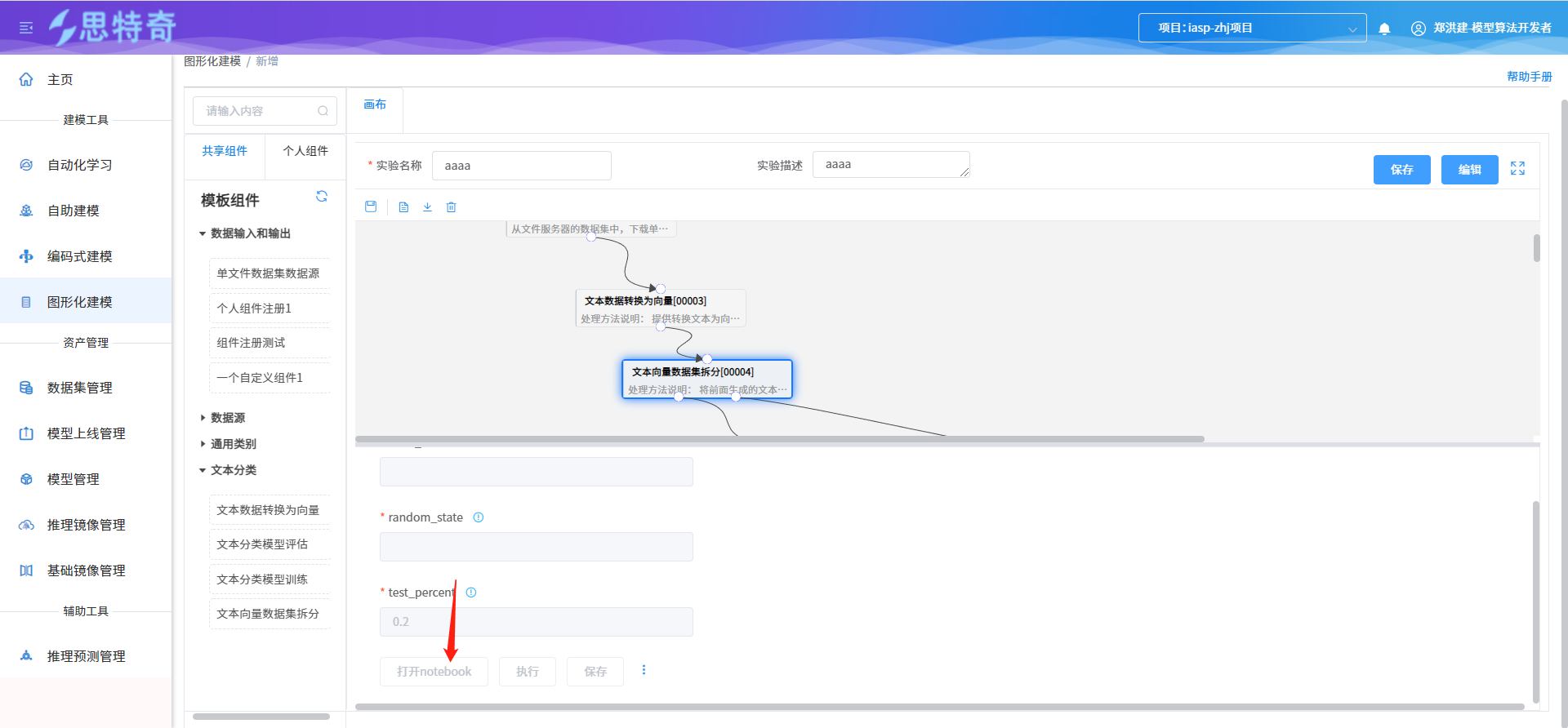
- 针对流程中组件设置属性参数

- 组件节点启动,通过点对应组件的执行按钮

- 针对组件为jupyter节点的组件可通过打开notebook按钮进入notebook
步骤三:查询组件执行结果数据及执行状态
组件执行成功后通过选中对应组件可通过数据展示处查询组件输出结果数据
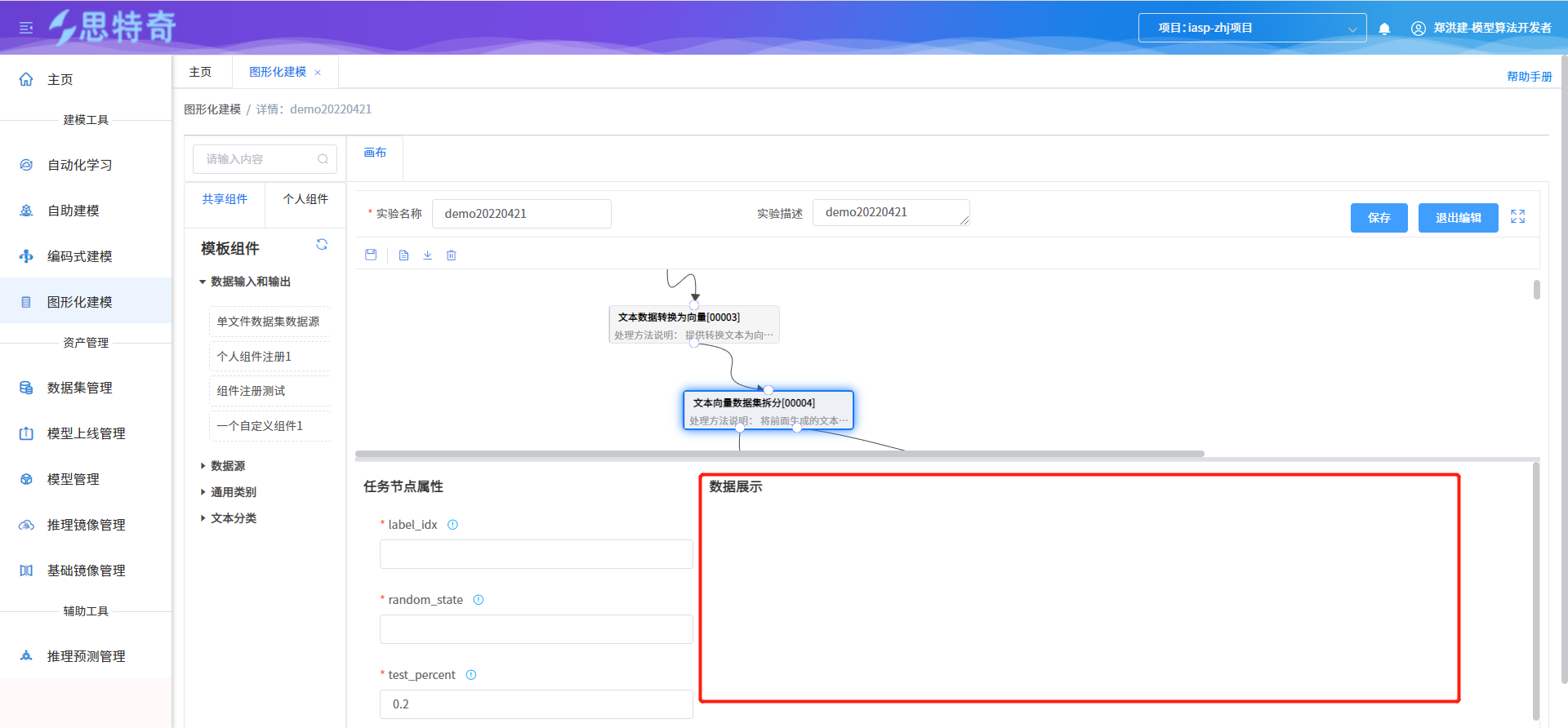
编码式建模
模型算法平台为AI开发者提供了线上notebook功能,开发者可在notebook中完成数据预处理、模型训练、预测、开发等操作。
本章节提供了一个手写数字识别的样例,您可以使用此示例,在Notebook中一站式完成模型训练,并上传图片进行预测。
开始使用样例前,请仔细阅读准备工作罗列的要求,提前完成准备工作。使用Notebook完成模型构建的步骤如下所示:
- 步骤1:准备预测数据
- 步骤2:nootbook资源创建
- 步骤3:使用Notebook训练模型并预测
步骤1:准备预测数据
开发者可通过LZ 8bit网站创建对应的预测手写字图片用于预测的数据,创建完成后可保存到本地目录中。
步骤2:nootbook资源创建
- 登录模型算法平台,点击菜单”编码式建模”
- 进入模块后选择新增编码式建模
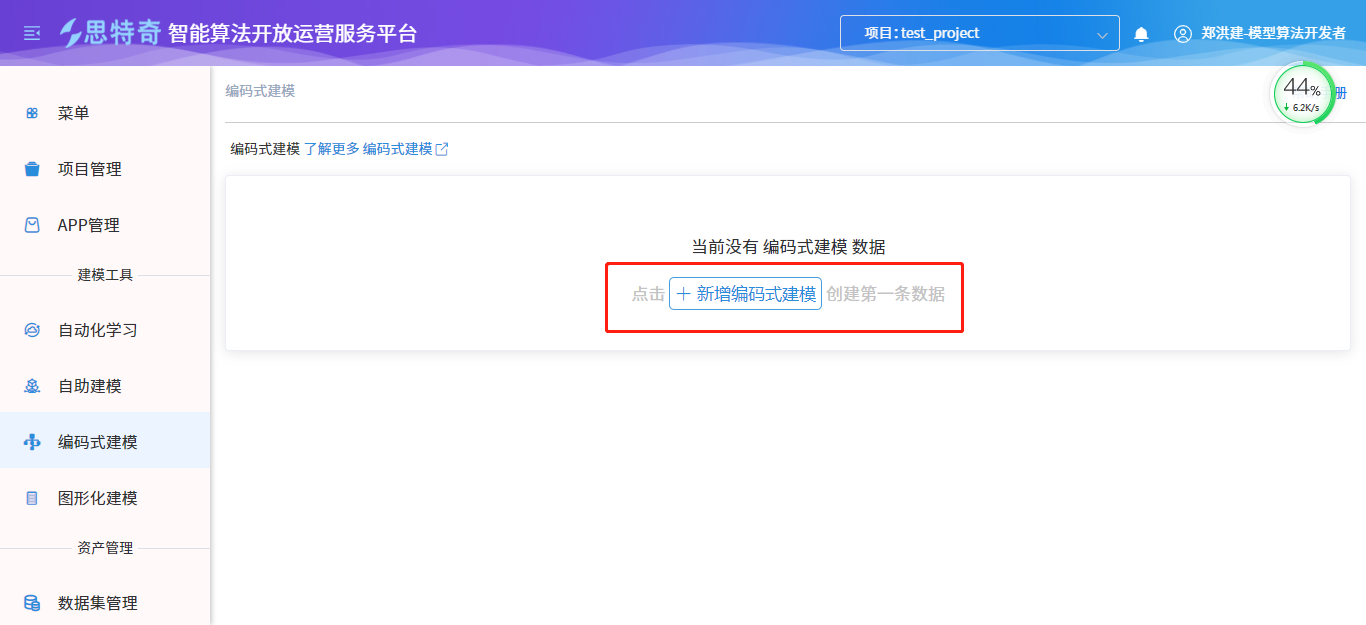
- 输入notebook基本信息,点击确认完成notebook创建
| 参数 | 说明 |
|---|---|
| 实验环境名称 | 用于唯一标识创建的notebook |
| 实验环境描述 | 用于描述notebook相关的实现内容 |
| 基础镜像 | 用于创建notebook容器的基础镜像,系统自动的基础镜像,支持git操作 |
| 资源规格 | 用于创建notebook容器的资源规格,可选cpu、gpu、内存、存储 |
步骤3:使用Notebook训练模型并预测
- notebook创建完成后待容器状态为运行中即可打开notebook,操作栏中分进入lab模式、进入notebook模型两种。其中进入lab模式支持git相关操作。
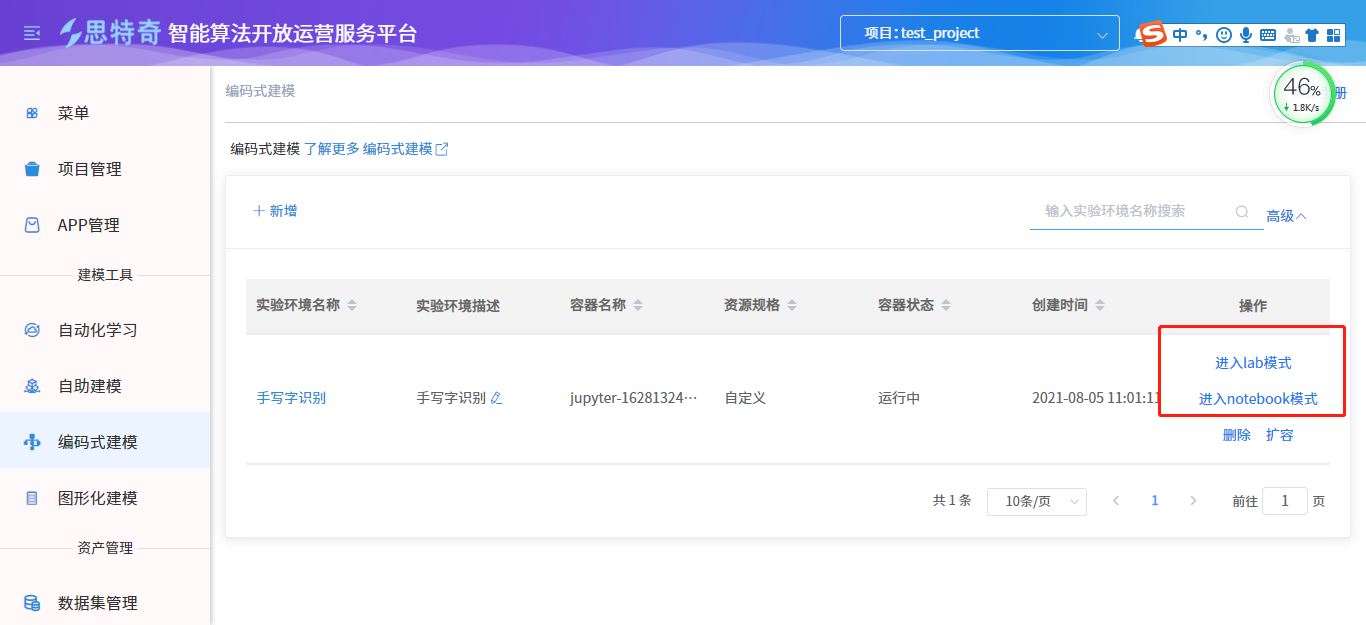
- 点击进入对应模式,通过new python3创建开发文件
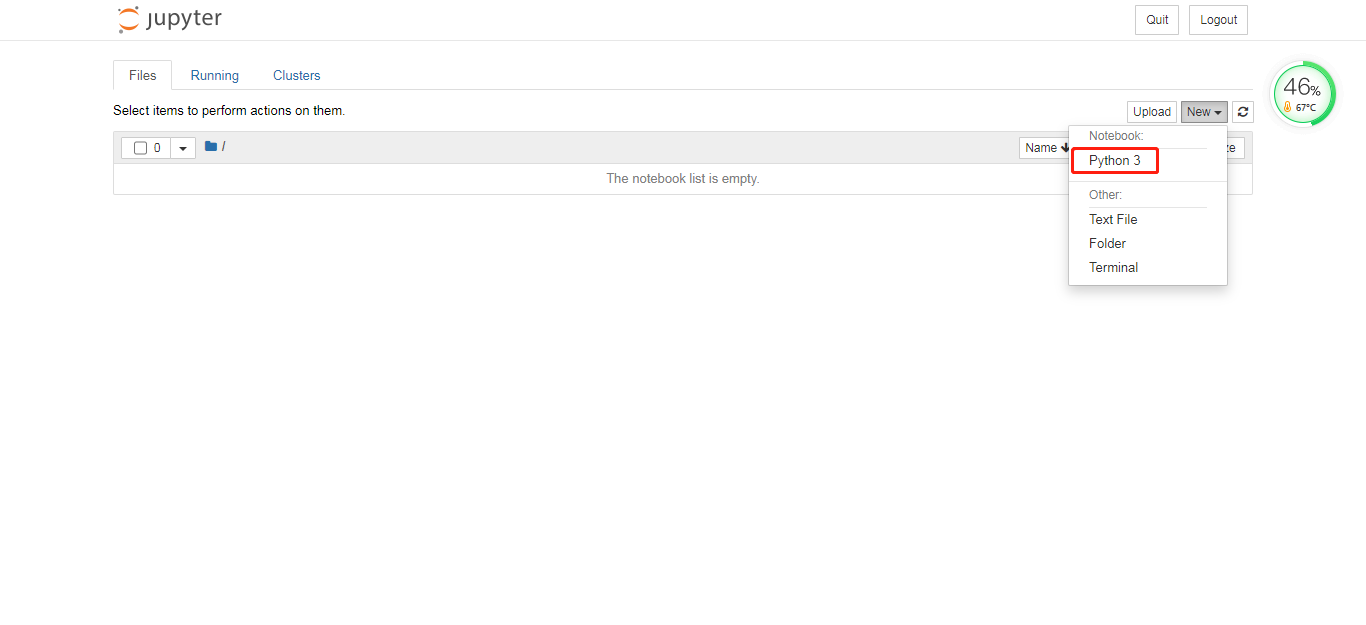
- 修改文件命名为iasp
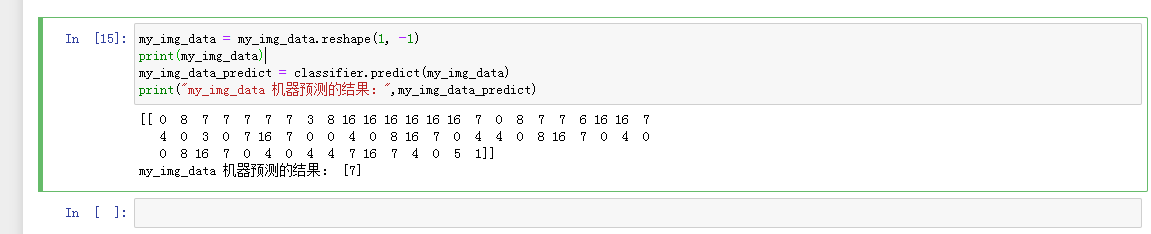
- 安装手写字识别训练的相关依赖包,通过Terminal pip install进行包安装sklearn、matplotlib、PIL、numpy

- 获取训练数据和训练数据的答案,并且简单测试下数据

- 使用SVM算法模型,进行学习

- 上传预测数据集图片,执行预测
数据中台融合
模型算法平台提供与数据中台融合环境,通过创建spark建模容器环境,并基于jupyter进行sparkml建模开发。训练过程可使用数据中台算力进行建模训练,在jupyter中进行spark任务提交,通过spark web界面进行查询任务执行情况。推理预测可通过访问hdfs批量预测数据进行预测,预测的结果文件同步保存到hadoop中。还可通过在建模容器中配置cron定时脚本进行进行定时执行spark训练任务。
此节以预测生育率模型训练样例演示数据中台融合过程。
准备工作
- 训练数据准备,hdfs存储
- 有创建spark环境建模容器
- 进行saprkml建模开发
- 提交spark训练任务
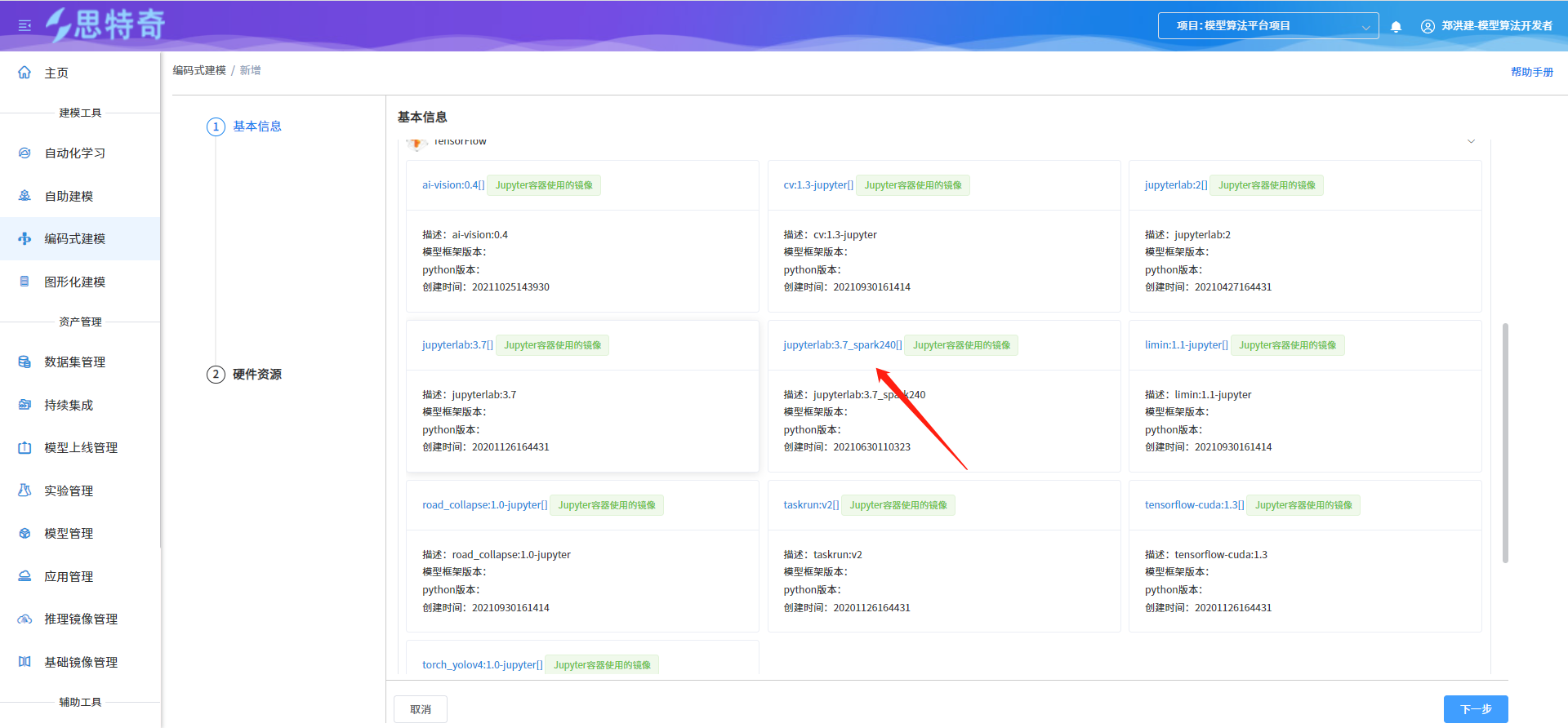
步骤一 创建spark环境建模容器
- 通过编码式建模功能创建spark开发环境建模容器
- 选择jupyterlab:3.7_spark240基础镜像
步骤二 训练数据集上传hdfs
建模容器创建完成后打开jupyter notebook,jupyter中集成hadoop环境和spark环境。 通过jupyter terminal进行集成的hadoop环境访问,并进行训练>数据集上传。
- 通过数据集管理生成训练数据集
- 通过数据集管理同步至容器功能将训练数据集同步到jupyter容器
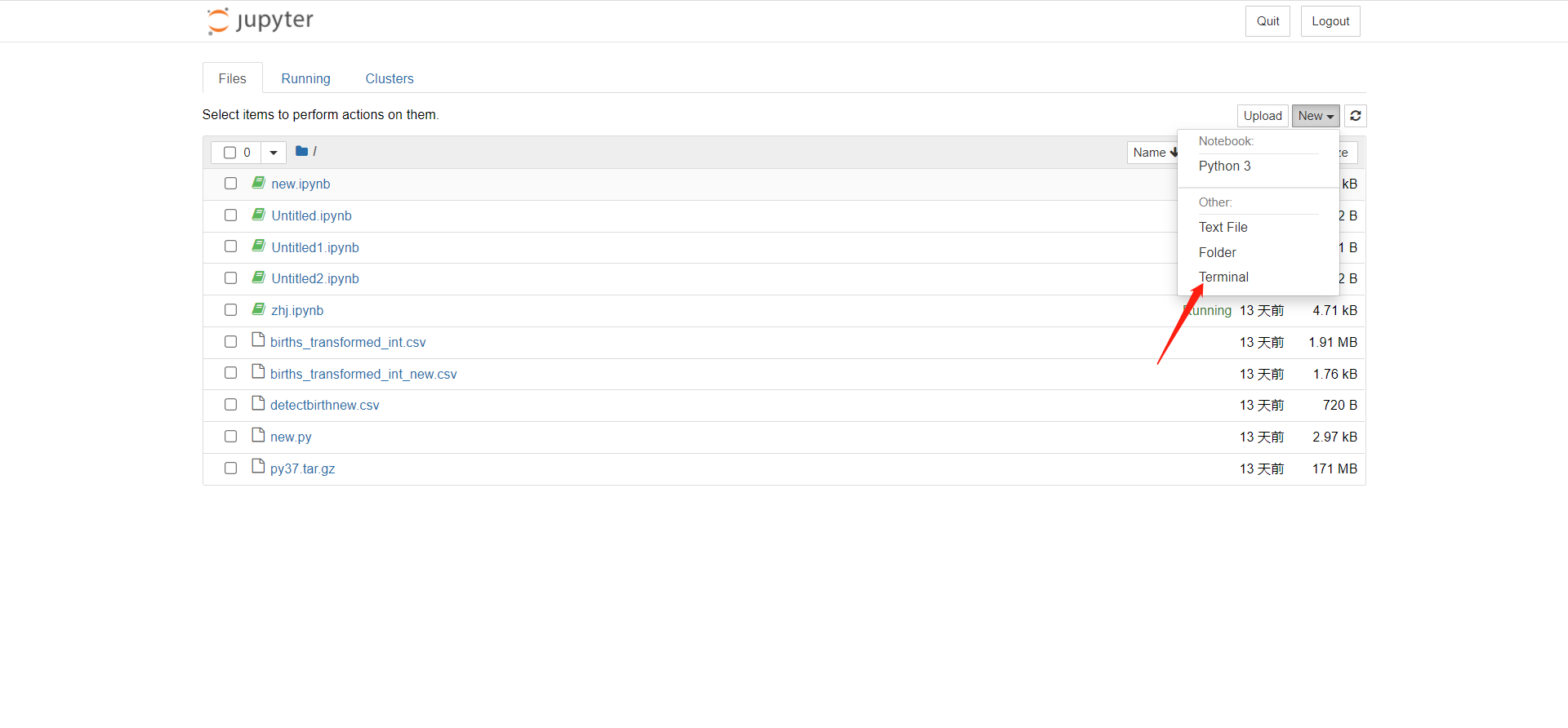
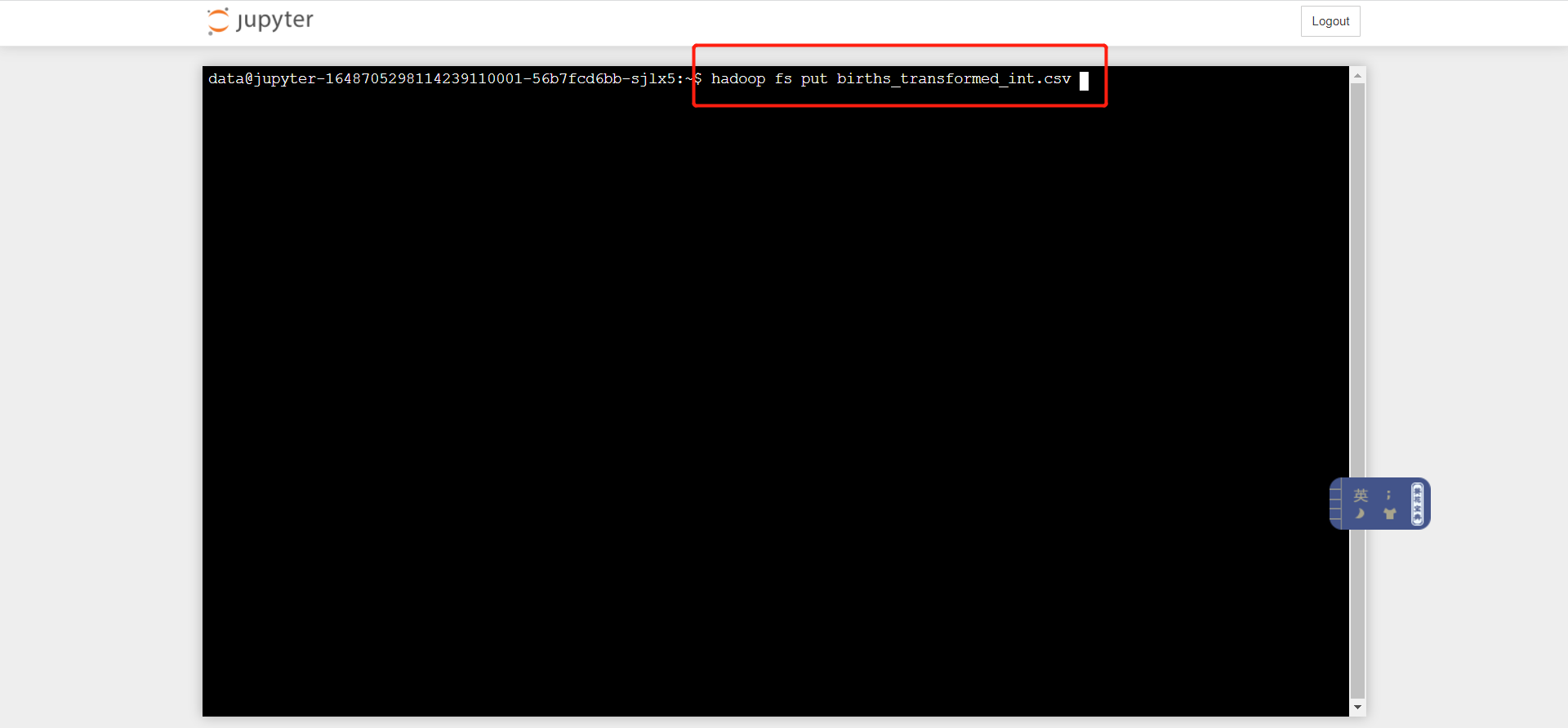
- 通过notebook中集成的hadoop环境进行训练数据集上传到hdfs,执行命令:hadoop fs -put births_transformed_int.csv
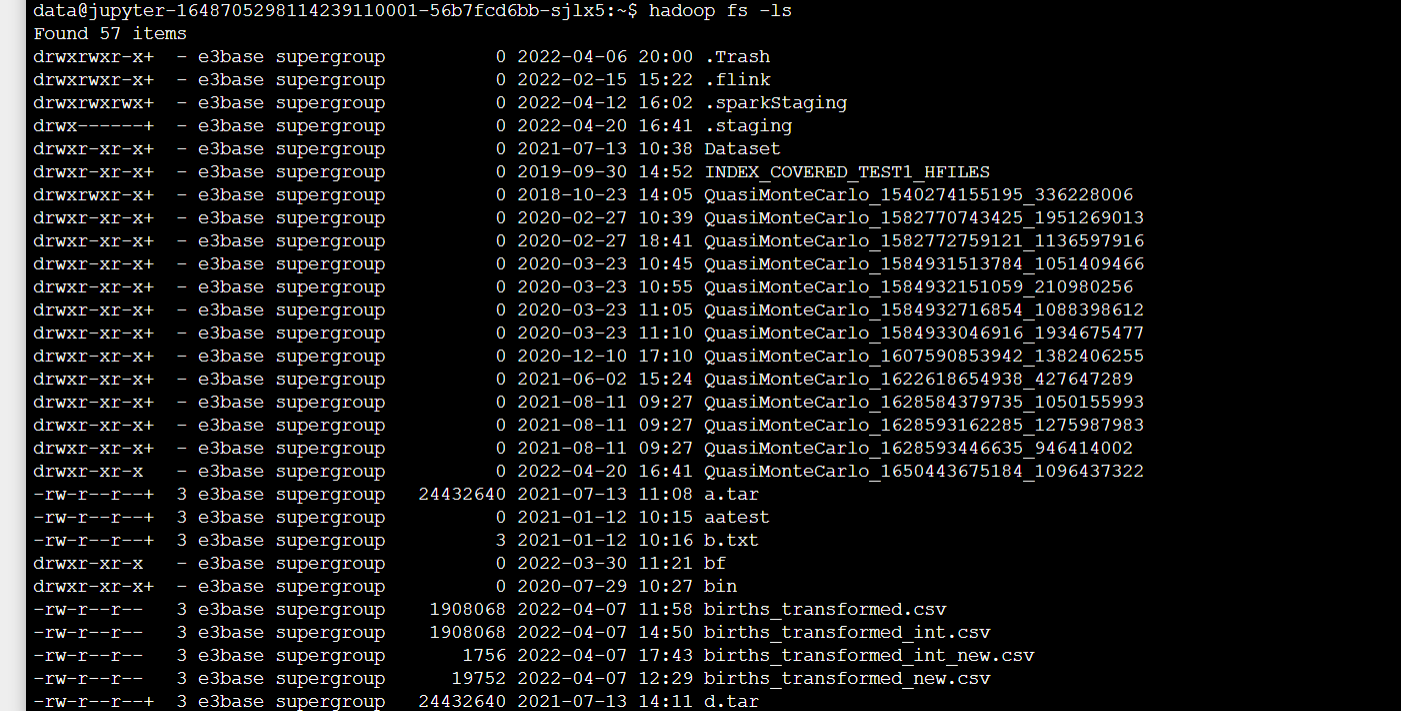
- 上传完成后通过命令hadoop fs -ls查询hdfs训练数据集文件
步骤三 建模训练代码开发
- 通过terminal进行依赖包引入

- spark应用创建

- 加载hdfs训练数据集
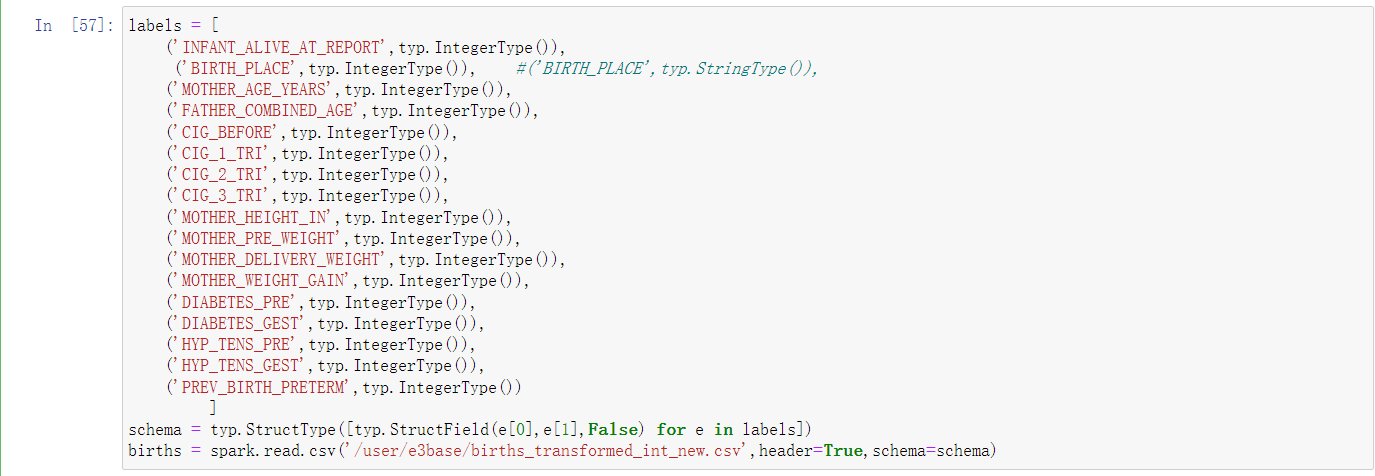
- 生育率预测模型训练
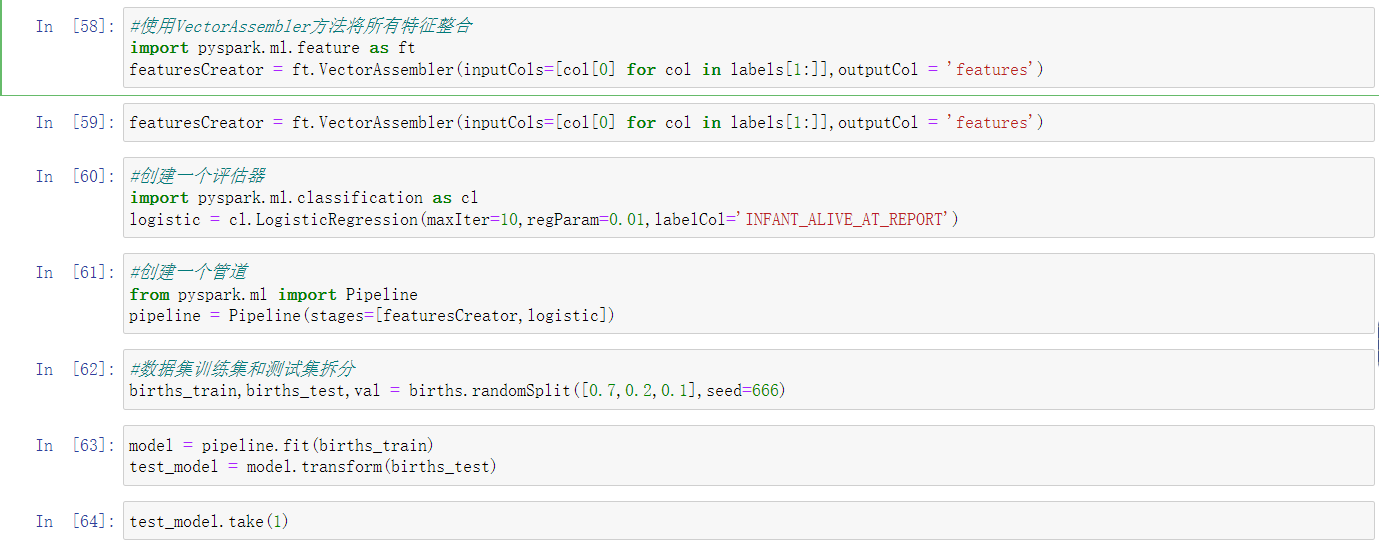
- 生育率模型评估

- 模型保存到hdfs

- 生育率模型预测

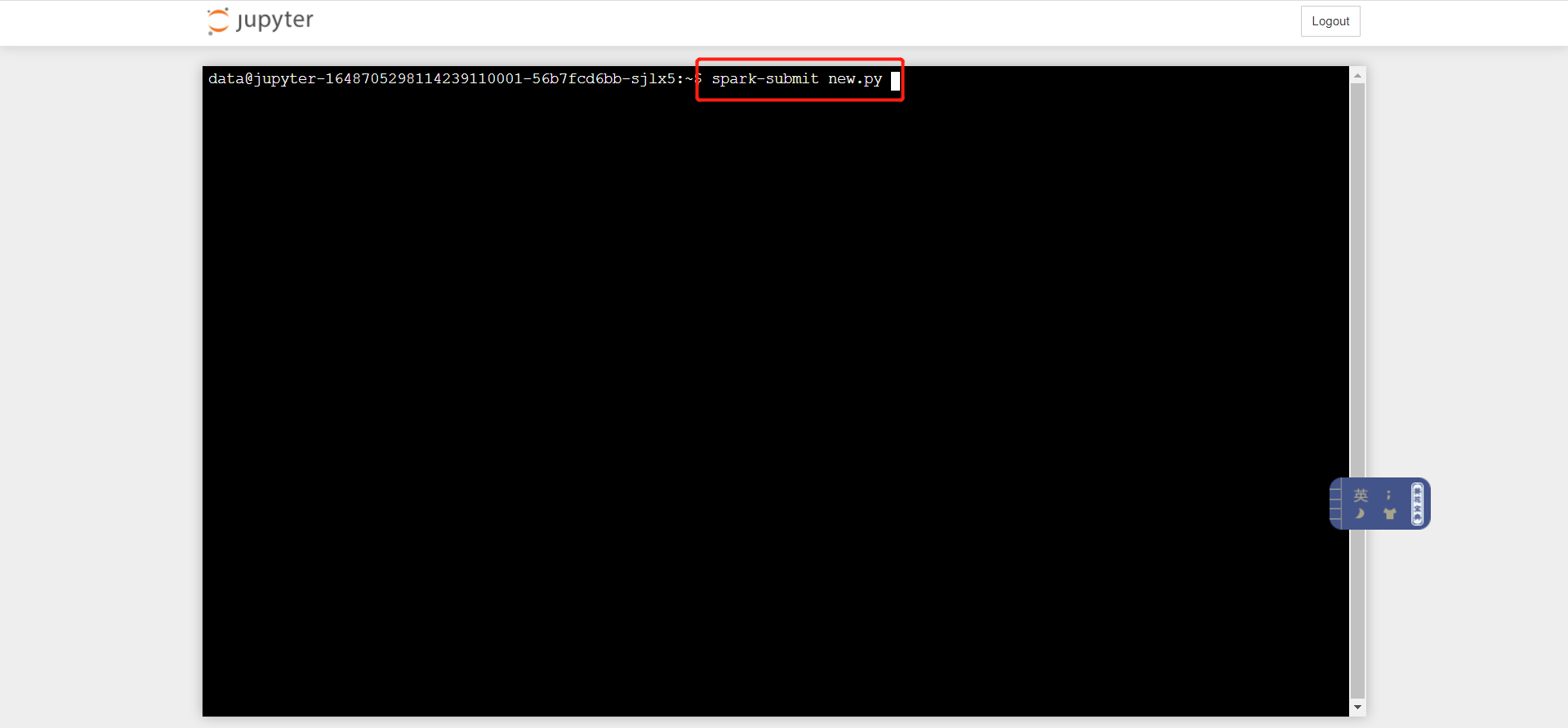
步骤四 spark训练任务提交
通过jupyter中集成的spark环境,执行spark-submit提交
数据回流
通过推理预测服务调用的阈值情况进行数据筛选,创建不和阈值的数据回流任务,针对回流的数据平台进行二次标注,二次标注后的数据转换为模型可识别 的标注数据,并上传到生成的数据同步到开发容器中,进行模型的二次优化训练。
本章节以手识识别能力为例进行数据回流操作
步骤一 创建手势识别回流任务
- 打开数据回流模块
- 点击新增,数据回流基本信息、能力信息、标签信息
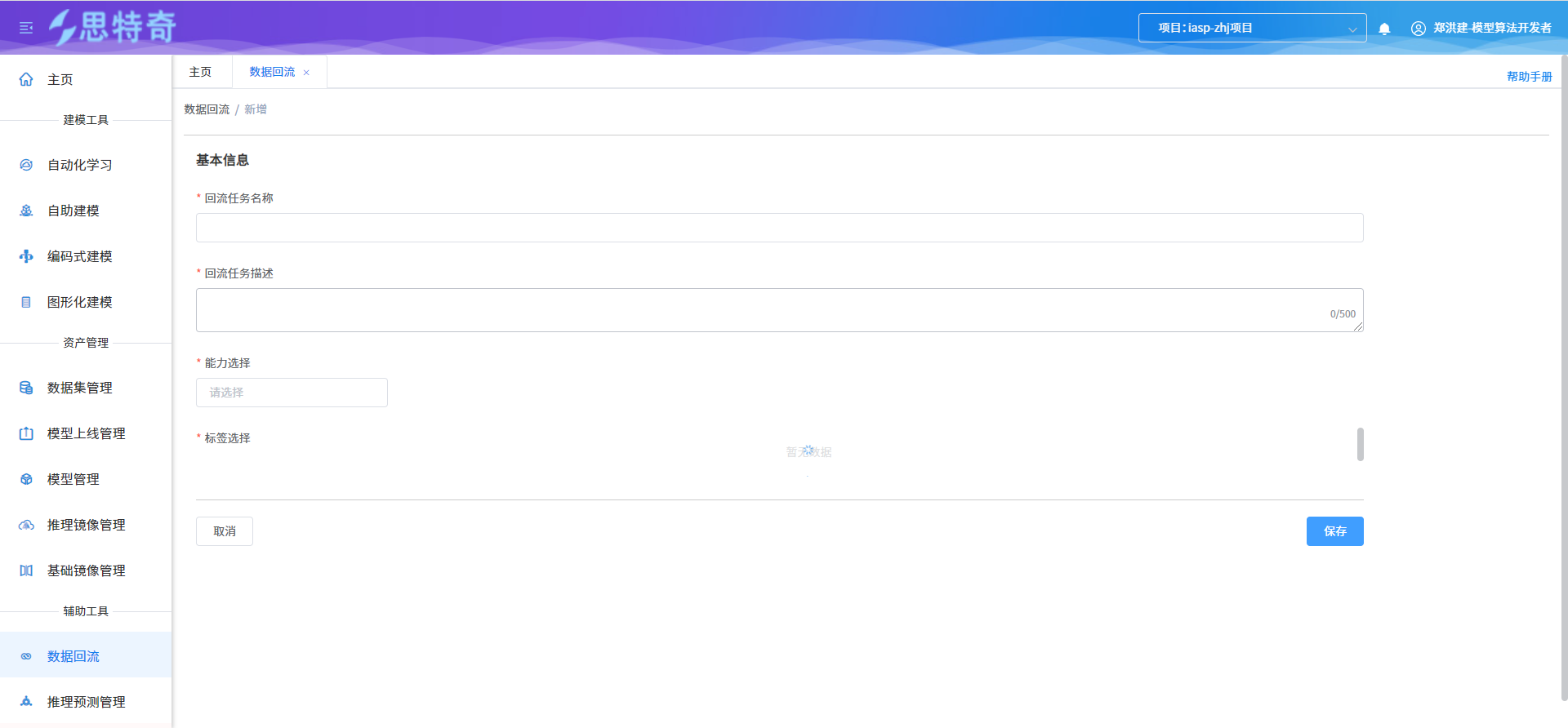
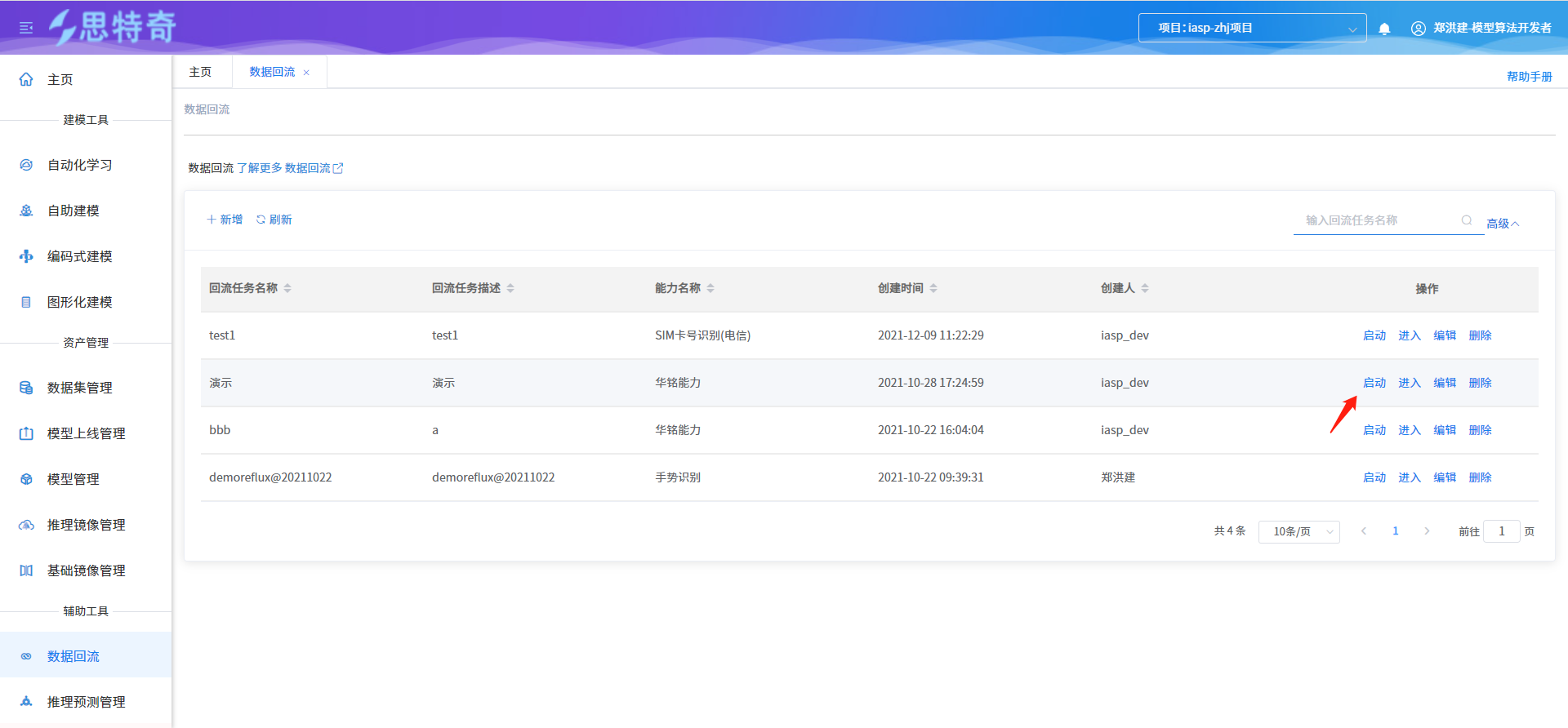
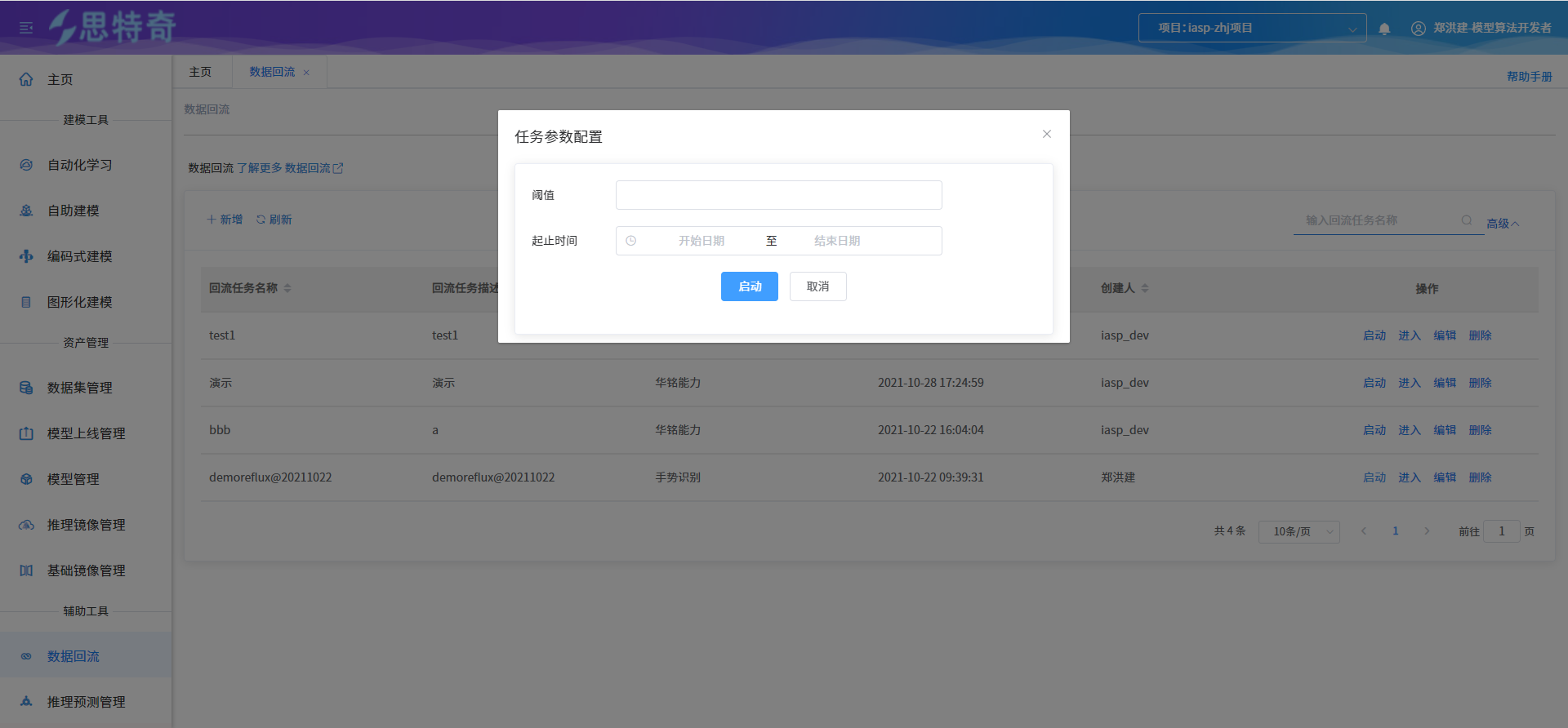
步骤二 启动回流任务
- 选择创建的任务,点击操作列启动
- 输入回流时间及对应阈值
- 回流任务启动后会生成对应的回流数据集,可在数据集管理模块查询
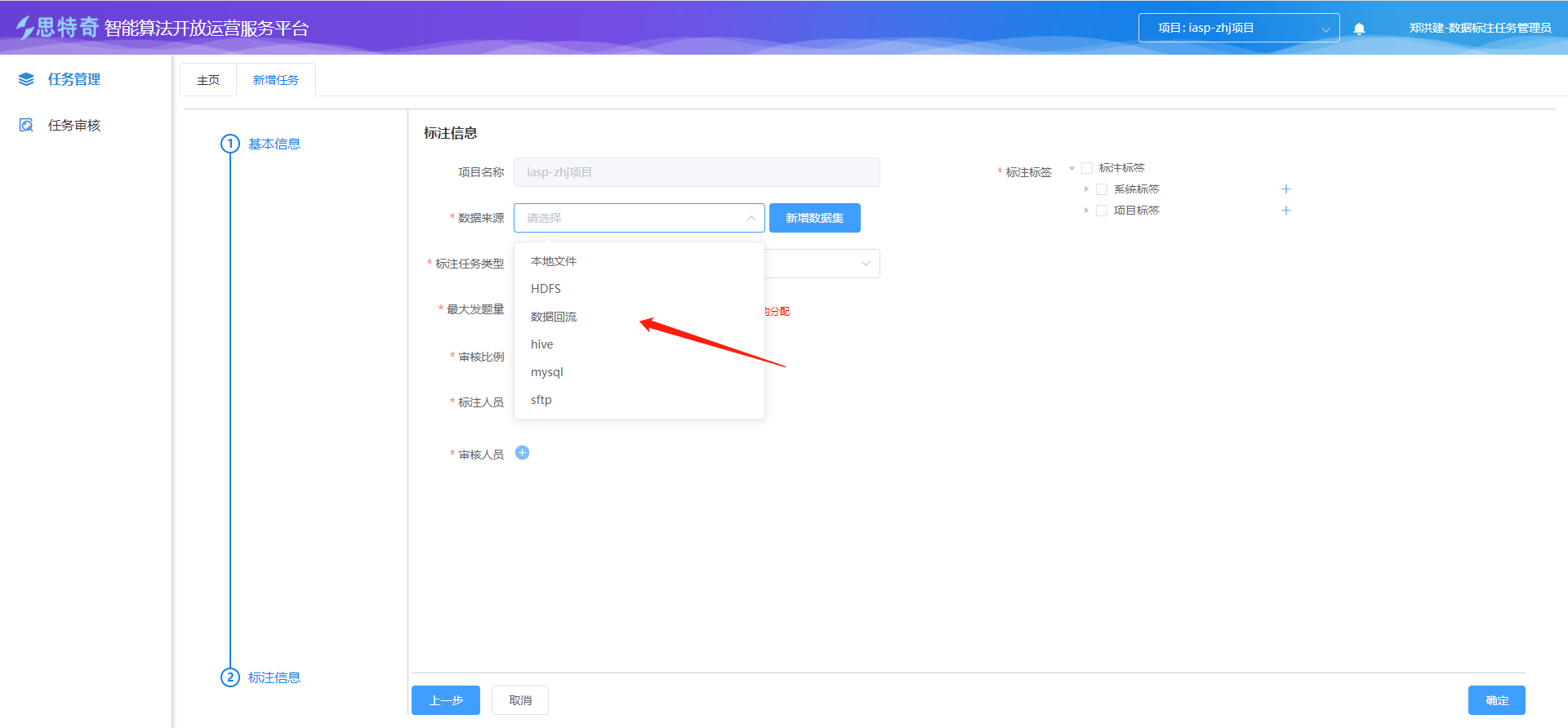
步骤三 创建回流标注任务
- 进入标注平台
- 创建回流标注任务
- 选择回流生成的数据集
步骤四 回流数据集标注
- 进入标注人员角色
- 对生成的回流标注任务进行标注
步骤五 标注完成的任务进行导出
- 导出标注任务
- 数据集管理模块查询导出生成的数据集
- 数据集上传至开发容器